die frage ist berechtigt, xoxos.
auch der vergleich mit der dot.com blase zur jahrtausendwende ist naheliegend. ich sehe aber einen entscheidenden unterschied zu damals, es ist die geschwindigkeit der ganzen entwicklung. die llm-modelle (large language model) entwickeln sich in rasendem tempo, praktisch im monatsrythmus kommen verbesserte modelle auf markt.
w�hrend es zu dot.com zeiten jahre brauchte, bis erste firmen schwarze zahlen schrieben geht es nun deutlich schneller. ich denke, bereits in einem halben jahr, in q1/26, werden wir erste profitable zahlen von reinen ki unternehmen (also nicht zulieferer wie nvidia, welche schon jetzt rentieren) sehen.
ps: was mich aktuell am meisten st�rt an den ki-modellen ist ihre extreme us fixierung. da sie mit amerikanischen daten in englischer sprache trainiert werden ist das auch nicht verwunderlich, aber entweder wird das in zukunft besser oder wir hier in europa m�ssen dringend eigene llm entwickeln, so wie china das auch schon macht.
|


 Thread abonnieren
Thread abonnieren


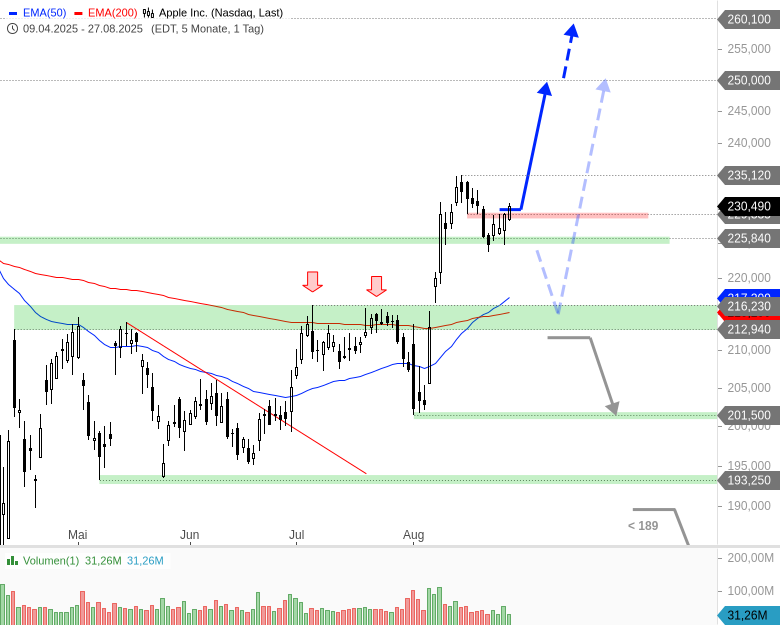
 Chart analysieren
Chart analysieren